

“Survivor bias is the logical error of concentrating on entities that passed a selection process while overlooking those that did not. This can lead to incorrect conclusions because of incomplete data.”
— Wikipedia”

{kind=link}
Survivor bias is a cognitive bias, a shortcut in our thinking to allow rapid decisions with little energy usage.
Undoubtedly, you’ve already seen this diagram of the plane. It’s an extremely common image, although the lessons from it aren’t always apparent. During World War II, they would look at returning planes to see where they had taken damage so that they could improve on the design. Each red dot indicates a bullet hole, where the plane had taken some damage.
It would seem natural to assume that any area on the plane that had a large clustering of bullet holes was an area where the plane needed reinforcing and yet that would be an example of survivor bias.
What the Statistical Research Group determined was that the interesting part of the data wasn’t what they could see (bullet holes) but rather what they couldn’t see. They determined that each bullet hole was a place where the plane could be hit and yet still return to base. It was in those places where there were no obvious holes, that the plane was vulnerable. If it was hit there, it would crash and therefore there would be no data available.
In the diagram above, you can still see the overall structure of the plane and so you can get some sense of where the data is missing. This is not so obvious when we’re looking at most data, however. Consider this cycletime scatterplot:
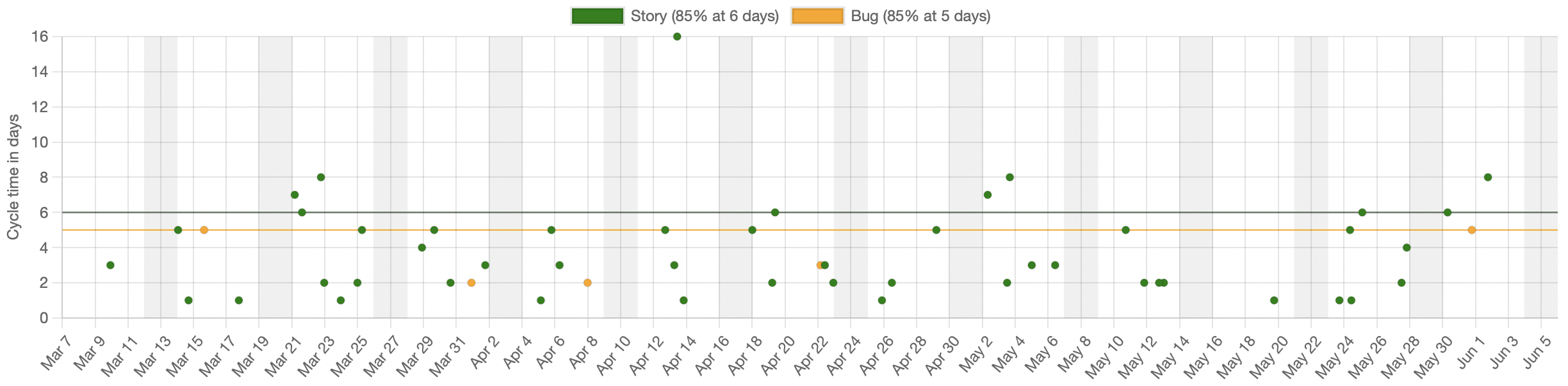
How much of the full data set is included in this chart? We don’t know. There’s no way to know just from looking at this. Survivor bias will lead us to believe that this is all the data and we will make decisions based on what is in front of us.
What if this chart only contained 10% of the overall data? Would our conclusions still be robust? They might if the sample we see here is representative of the whole, but we have no way of knowing if that’s true and survivor bias will just accept what we see. Unless we have a reason to question the accuracy of the data, we will blindly make decisions based on what we see and will ignore what isn’t.
How could we make it more likely that people will interpret the data correctly? We could explicitly call out how much of the overall data is included, to make people consider if the remaining data is good enough for effective decision making. We do this in the JiraMetrics tool, although many people still ignore the disclaimers.